A small test program has been written in every one of the following languages. The programs convert numbers to Roman Numerals and back to numbers. Simple, but it utilizes many programming features, such as functions, loops and conditionals. The test program produces identical output when run using a standard compiler or interpreter. In addition to Parsing each test program, they are all Interpreted and Transformed to C#, Java and Python. Transformation is still a work-in-progress; we prefer to do it right, rather than quickly.
Pick a Language:
Planned Languages: Haskell, Natural, RPG
Ⓣ means Transformation is working (23 of 29)
Identical Output from all 29 versions of the Romanamor program:
Converted 812 to DCCCXII as expected Converted 43 to XLIII as expected Converted 49 to XLIX as expected *** Number must be in the range 1 to 3999, not 4000 *** Error converting 4000, got Error instead of MMMM Converted CCCXIV to 314 as expected Converted MCMXCIX to 1999 as expected Converted CXXXI to 131 as expected Converted III to 3 as expected *** Invalid roman numeral: MMMM starting at 4 *** Error converting MMMM, got 0 instead of 4000 Validated all conversions from 1 through 3999 |
A few conversions from numbers to Roman Numerals are checked, followed by a few conversions from Roman Numerals back to numbers. Finally, an exhaustive set of conversions from a number to a Roman Numeral and back is checked for all valid numbers, from 1 to 3999.
See the Wikipedia page Roman_numerals for more details. We are using the "Standard form" with IV for 4 instead of IIII (*).
Most languages also have Expressions.xx and Statements.xx programs. These little test programs are used to verify that our interpreters are correct. For example, does 5 / 4 equal 1 or 1.25 ? And how does each language support loops with decreasing values? There are many variations between languages.
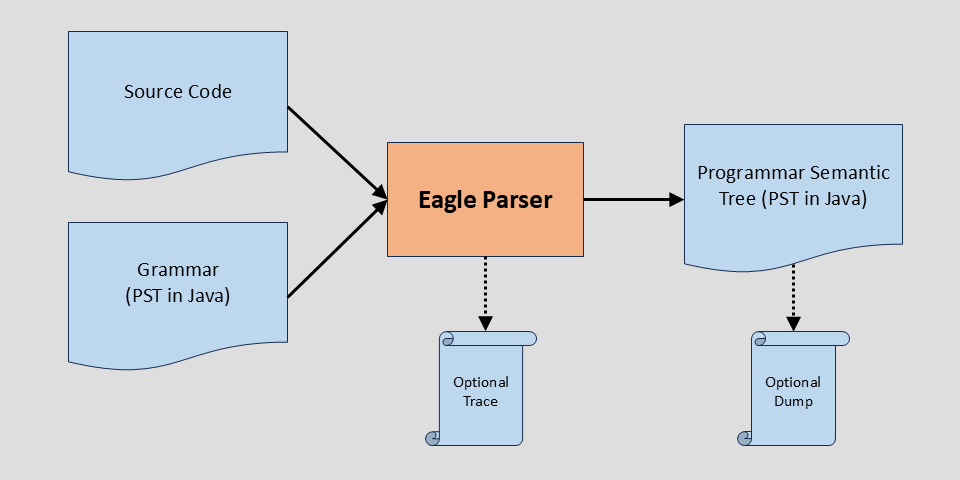
| Parsing PhaseParsing takes a source program and a grammar and produces a Programmar Semantic Tree (PST). A PST is actually a Java Object that contains fields for all the components of each production rule in the grammar. The PST is stored as an XML file typically, and becomes a collection of Java objects once it is loaded. Optionally, the Parser can produce a detailed trace of all the production rules attempted, including those that did not match. A complete Programmar is available here. It is for the original Basic programming language, from half a century ago. |
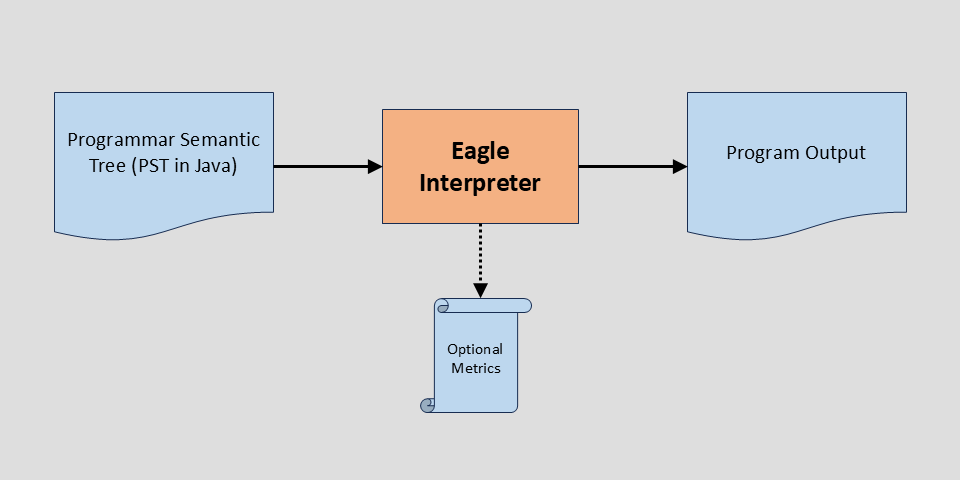
| Interpreter PhaseInterpreting a program generally involves running the program without a compiler or environment. These interpreters are incomplete but are designed to handle a significant part of each language. The key to the interpreters as we have implemented them is that all the logic with each statement, function or operator is kept with the grammar for the language element. For example, the interpreter for multiplication is in the same file as the grammar production rules. A significant output from the interpreters is a collection of relevant Metrics. Some languages, such as Python, do not support strong typing. Given a Python function, you cannot tell by inspection if the arguments are lists, numbers, strings, etc. During our Interpreter Phase, we collect metrics like that so assist further analysis, especially transformation. |
Transformer PhaseGenerally speaking, Transformation is much more difficult than Interpretation because most decisions need to be made before running the program. For this reason, we interpret the program first, and collect metrics to help make those decisions. At this point, we only transform to Java, C# and Python. Adding an additional transformation target is feasible if the new target language supports classes, methods, etc like Java or C#. |